Tesseract-OCRでOCR 設定 Ubuntuで
TesseractといえばオープンソースOCR(文字認識)の定番ライブラリと思いますが、私も仕事で多少触っていますので、基本的な使い方、注意点をメモって見ます。
2019年5月時点の記事です。
Tesseractの現在使われているバージョンは3と4の2つありますが、認識精度は当たり前ですが、4 のほうがよいですので、可能でしたらバージョン4を使うほうがよいです。
ただし私の環境のUbuntu16.04ですと標準のリポジトリからインストールすると3になってしまいます。Ubuntu18.04ですとbetaですが、バージョン4になっていますね。
Ubuntu16.04でもがんばればTesseract4インストールできますが、ソースからもってきてコンパイルインストールなので、私のようなアマチュアLinux愛好家にはちょっと敷居が高いですね。一応私でも出来ましたが、この部分は自信ないですので、記載しません。
インストールは一応以下でUbuntu16.04/18.04でどちらも同じです。
$ sudo apt-get install tesseract-ocrバージョン確認コマンド
$ tesseract -v結果
#Ubuntu18.04
tesseract 4.0.0-beta.1
leptonica-1.75.3
#Ubuntu16.04
tesseract 3.04.01
leptonica-1.73
#Ubuntu16.04 気合でTesseract4を入れた場合
tesseract 4.1.0-rc1-15-gc02f
leptonica-1.74.4
対応している言語を確認します
$ tesseract --list-langsjpnが出てこないで、jpnが必要な場合はデータ追加です。
$ sudo apt-get install tesseract-ocr-jpn当然ですが、apt-getでtesseractをインストールしていない場合は手動でjpnデータをインストールする必要があります(割愛。。)。
動作確認
OCRしたい画像ファイルが日本語が含まれているtest.jpg、出力のテキストファイルをoutput.txtとしたい場合は
$ tesseract test.jpg output -l jpnとりあえずこれで何か文字は出力されると思いますが、現実的にテストではなく何か実際に利用シーンがある場合にはより精度をあげるために’psm'(Page Segmentation Modes)オプションを指定してやったほうがベターです。これが微妙に4系と3系でオプションのわたし方が違うようですので、注意が必要ですね。
4系は’–psm’ですが、3系は’-psm’ですね。私のように諸事情で4系、3系を併用している場合は面倒です。。私が普段利用しているのはpsm 7です。あと8でしょうか。これをつけると正しく認識できることが結構ありました。画像認識のプロではないので、理由はわかりませんが。
7 Treat the image as a single text line.
8 Treat the image as a single word.実際のコマンド
#tesseract4系
$ tesseract test.jpg output -l jpn --psm 7
#tesseract3系
$ tesseract test.jpg output -l jpn -psm 7私は実際の仕事ではOSのコマンドラインからではなくて、pythonのpytesseractでtesseractを呼び出していますが、ここでも4系、3系でpsmオプションを渡してやる場合にも、注意が必要ですね。以下のconfig=の部分になります。
#tesseract4系
output=pytesseract.image_to_string(Image.open('test.jpg'),config='--psm 7')
#tesseract3系
output=pytesseract.image_to_string(Image.open('test.jpg'),config='-psm 7')pytesseractを使った場合は–psmでも-psmでもエラーにはなりませんが、OCR結果が出力されませんね。OSコマンドラインから実行するとエラーを返してくれますが。
OCR実践
実際に以下のあいうえお画像ファイルをocrしてみました。
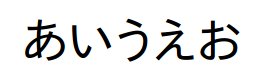
#tesseract4系
あい うえ お
#tesseract3系
あいうえおこの文字列画像に関してはなぜか4系で不要な空白が含まれてますね。。
ただこれ以外にもいろいろOCRしてますが、4系のほうが認識率は高いのは間違いないと思います。
ただ4系、3系でもOpenCVを使っていろいろ調整すると3系でも十分いけるような気がします。次はOpenCVとpytesseractを組み合わせた記事を書いてみたいと思います。